Desarrollo técnico de Manuscritos de América en las Colecciones Reales
1- PROCESO DE TRANSFORMACIÓN
1.1- Lectura del formato MARC y conteo de etiquetas
Como primer paso en el desarrollo, se construye una aplicación cuya función será leer los archivos MARC y suministrar información numérica sobre volumen de información, índices de aparición de campos y otros datos estadísticos.
Fruto de este primer proceso, se consigue una tabla de campos ordenada por número de instancias en el conjunto de registros. Esta tabla es la que servirá de base para la construcción de las tablas de transformación.
1.2- Tablas de transformación.
Usando como plantilla el listado de campos MARC, se establece la correspondencia MARC-TEI MASTER. Es una tarea compleja, ya que diferentes campos MARC darán lugar a una sola etiqueta MASTER o viceversa. Incluso es frecuente que diferentes subcampos MARC deban reconstruirse como diferentes etiquetas MASTER.
Ejemplos:
Relación de Campo Marc, conteo, transformaciones y notas.
| Campo MARC | Conteo | Transformación | Notas |
|---|---|---|---|
| 046 | 357 | $c: origDate[@notBefore] $e: origDate[@notAfter] |
Acotación de la fecha de origen del documento, en caso que $e no esté definido, se asume fecha exacta y se duplica el valor de $c en ambos atributos de |
| 300 | 1315 | $a: physDesc/extent $b: physDesc/support $c: physDesc/extent/dimensions |
Descripción física. Extensión, soporte y dimensiones. |
| 773 | 3466 | $g: msItem/locus $a: Referencia a registro fuente. |
$a: Este es el campo que referencia al documento fuente, sólo aparece en registros analíticos.$g: Locus. Posición del documento analítico en el fuente. |
1.3- Decodificación de registros.
A partir de la tabla de transformación, se desarrolla una aplicación para efectuar la conversión.
En una primera pasada, se decodifican y transforman los registros tanto analíticos como fuentes. Posteriormente se enlazan para construir los fuentes definitivos.
Con vistas a una posible extensión de la aplicación para llegar a la totalidad de campos MARC, se construye una librería base de acceso a campos y subcampos MARC, de esta forma, el módulo principal (clase, en JAVA), queda «limpio» de toda lógica de acceso a datos, centrándose así en el proceso de transformación.
El lenguaje utilizado para el desarrollo ha sido JAVA.
1.4- Construcción incremental de registros TEI MASTER
A partir de un análisis exhaustivo de la norma MASTER y del subconjunto de etiquetas MARC que aparecen en el catálogo se implementa la transformación de una forma incremental, en vistas a la claridad y a la extensibilidad.
Detalle del código fuente:
[...]
public String construyePhysDesc(Vector c)
{
String salida="";
salida+=construyePhysDesc_support(c);
salida+=construyePhysDesc_extent(c);
salida+=construyePhysDesc_msWriting(c);
salida+=construyePhysDesc_decoration(c);
salida+=construyePhysDesc_bindingDesc(c);
salida+=construyePhysDesc_foliation(c);
salida+=construyePhysDesc_additions(c);
if (salida.length()>0) return "\t\n"+salida+"\t\n";
else return"";
}
[...]
public String construyePhysDesc_bindingDesc(Vector c)
{
String salida="";
Vector aux;
aux=valorSubCampo(c,"852","r"); // Encuadernación ($r)
for (int i=0;i<aux.size();i++)
salida+="\t\t\t
"+aux.elementAt(i)+"
\n";
if (salida.length()>0)
return "\t\t\n"+salida+"\t\t\n";
else return "";
}
[...]
Podemos observar como la estructura TEI MASTER se encuentra embebida en el código fuente (hard-coded). Esto se ha hecho así por razones de eficiencia. Resulta extremadamente sencillo diseñar plantillas que asocien elementos XML con campos y subcampos MARC, pero esto haría que el proceso resultara más lento, así como compleja su comprensión a partir del código.
1.5- Reconstrucción de registros TEI-MASTER
Durante el proceso de transformación, se discriminan los registros según si son fuentes o analíticos, y la construcción del XML resultante se efectúa en un sentido u otro.
A partir de la existencia o no del campo MARC 773 (asiento de documento fuente) se decide como debe reconstruirse el registro.
Detalle del código fuente:
[...]
if (!analitico)
{
salida.append("");
salida.append("\n");
salida.append(construyeMsIdentifier(campos));
salida.append(construyeMsHeading(campos));
salida.append(construyePhysDesc(campos));
salida.append(construyeHistory(campos));
salida.append(construyeAdditional(campos));
salida.append(construyeMsContents(campos));
salida.append("\n");
}
[...]
Ejemplo de transformación de un registro analítico. Pulsar sobre la imagen para ampliar.

1.6- Enlace analíticos-fuentes
Para enlazar los registros fuente con sus analíticos se construye un vector por cada registro fuente con partes. En el sentido fuente->analítico, se marca donde debe ir el conjunto de partes.
Detalle del código fuente: (Agrupación de analíticos)
[...]
if (!analitico) fuentes.put(desc_fuente,temp);
else
{
temp=sustituye(temp,"~~~IDNO~~~",desc_fuente);
if (!analiticos.containsKey(desc_fuente))
analiticos.put(desc_fuente,new Vector());
((Vector)analiticos.get(desc_fuente)).addElement(temp);
}
[...]
Detalle del código fuente: (Inserción de analíticos en el fuente correspondiente)
[...]
while (e.hasMoreElements())
{
String idnoIter=(String)e.nextElement();
Vector analiticosVec=(Vector)analiticos.get(idnoIter);
cont_fuentes++;
String contenido=(String)fuentes.get(idnoIter);
if (analiticosVec==null || analiticosVec.size()==0)
contenido=sustituye(contenido,"~~~ANALITICOS~~~\n","");
else
{
StringBuffer concat_analiticos=new StringBuffer(32768);
for (int i=0;i<analiticosVec.size();i++)
concat_analiticos.append(analiticosVec.elementAt(i));
contenido=sustituye(contenido,"~~~ANALITICOS~~~\n",
concat_analiticos.toString());
}
}
[...]
1.7- Grabación masiva de registros
Una vez efectuada la transformación y enlazados los registros analíticos con los fuentes, se graba el catálogo completo, resultando un fichero XML por cada registro fuente.
1.8- Posibles extensiones.
Si bien la aplicación de transformación se realizó pensando en el caso específico del catálogo de Palacio Real, resultaría muy sencillo generalizarla para otros casos.
La principal línea de actuación sería desarrollar un formato de archivo con el que especificar los detalles de transformación, esto nos permitiría transformar MARC en cualquier tipo de norma XML. Otra posibilidad sería convertir los registros fuente en XML-MARC para realizar las transformaciones con hojas de estilo XSL.
1.9- Revisión experta.
Si bien la salida del proceso de transformación consiste en archivos XML bien construidos y válidos según la DTD de MASTER, se hace necesaria una revisión de los ficheros XML generados. Esto es así por la dificultad derivada de tratar lenguaje natural, así como por la posible aparición de errores en la catalogación original en MARC.
En este paso, se realiza también un marcado de autoridades. El enlace de las autoridades en los registros fuente con el archivo de autoridades se construye mediante hojas de estilo XSL.
2- MAQUETACIÓN
2.1- Obtención de los ficheros de entrada
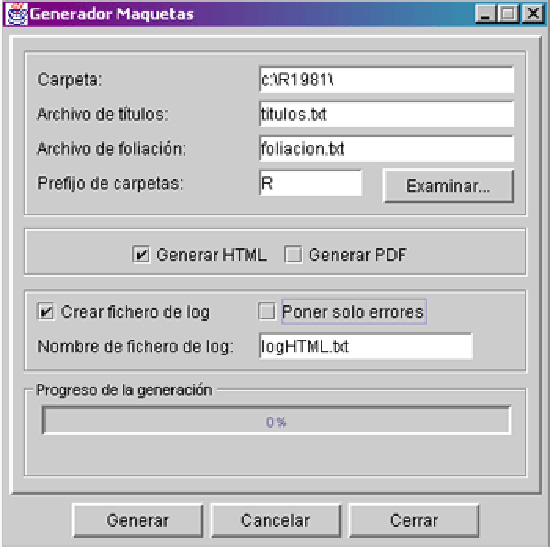
La maquetación automática tiene como entrada:
- Ficheros de imagen estructurados
- Relación de títulos de registros analíticos
- Relación de foliación
Los ficheros de imagen se estructuran en directorios, de forma que las imágenes de un registro analítico se encuentran en un directorio de su registro fuente.
La relación de títulos se obtiene automáticamente del registro XML mediante una hoja de estilo XSL. Esta hoja de estilo también extrae la información sobre la extensión de la parte.
Los archivos de foliación no pueden construirse de forma automática, ya que deben revisarse los ficheros de imagen para detectar errores en la foliación original, que deben representarse en la maquetación.
2.2- Automatización de la maquetación.
Con los ficheros de entrada comentados en el punto anterior, la maquetación se realiza de forma completamente automática mediante una aplicación desarrollada a tal efecto.
La salida se realiza en dos formatos:
- HTML. Se construyen los ficheros HTML necesarios para navegar por el conjunto de documentos, así como un índice.
- PDF. Se construye un fichero XML a partir del cual se genera el PDF mediante formating objects (http://xml.apache.org/fop/).
Al mantener las colecciones de imágenes en directorios estructurados a partir del fuente, en una sola pasada se maquetan todos los registros analíticos, alcanzando así una gran productividad.
Interfaz del generador de maquetas:
3- CATÁLOGO ON-LINE
Para la recuperación de información de catalogación en formato XML del TEI-Master se ha adaptado la estructura de datos (árbol TrieP) de búsquedas en formato MARC ya existente. En ésta estructura se introduce cada una de las palabras a recuperar junto con las etiquetas y atributos de etiqueta que contienen a dicha palabra como prefijo, de forma que a la hora de recuperar información XML, se concatena la etiqueta con las palabras a buscar para acceder al árbol y obtener los identificadores de obra correspondientes, si los hubiere.
Al mismo tiempo que se introduce la información XML en el árbol de búsquedas, se guardan las diferentes etiquetas TEI_Master usadas en una lista, que será usada más tarde en los formularios de búsqueda que se presentan al usuario para facilitarle la selección de las etiquetas sobre las que se desea realizar la búsqueda.